


NVIDIA® ConnectX-6 VPI 200G MCX653106A-HDAT for Accelerated Machine Learning & Big Data Solutions



Positioning of ConnectX-6 VPI

In the wave of digital transformation driven by artificial intelligence and big data, network performance has emerged as a key bottleneck limiting the full potential of computing power. Traditional CPU-dependent network interface cards are increasingly inadequate in high-throughput, low-latency scenarios such as machine learning and real-time data analytics. The NVIDIA ConnectX-6 VPI series of network adapters was created specifically to address this challenge. With three core capabilities—200Gb/s bandwidth, sub-microsecond latency, and hardware offload acceleration—ConnectX-6 VPI redefines the performance boundaries of modern data center networking.
ConnectX-6 VPI (Virtual Protocol Interconnect) continues NVIDIA’s leadership in smart networking by becoming the first to offer seamless support for both InfiniBand and Ethernet protocols. It supports mainstream speeds such as HDR 200G and EDR 100G. One of its most groundbreaking innovations is the use of hardware virtualization technology to offload network protocol processing from the CPU to the network adapter itself. This significantly reduces host resource consumption and mitigates compute power waste caused by network congestion.
The MCX653106A-HDAT, a flagship model in the ConnectX-6 VPI lineup, is purpose-built for high-density data centers. It features dual QSFP56 ports and supports PCIe 4.0 x16 lanes, delivering up to 400Gb/s of full-duplex throughput. The MCX653106A-HDAT also supports block-level XTS-AES hardware encryption, enabling secure data encryption and decryption during transmission—ensuring both high security and minimal performance overhead compared to traditional software-based encryption methods.
Technical Specifications and Hardware Advantages
Breakthrough Connectivity
The NVIDIA ConnectX-6 VPI 200G MCX653106A-HDAT is engineered around a single-port 200Gb/s and dual-port 400Gb/s full-duplex architecture, setting a new benchmark for network adapter performance. Leveraging a PCIe 4.0 x16 interface, the card supports a data transfer rate of 256 GT/s on the server side, fully meeting the demands of real-time synchronization for terabyte-scale parameters in large-scale machine learning model training.
With flexible support for both 50G PAM4 and 25G NRZ signaling, the adapter intelligently adapts to varying network speeds, ensuring broad compatibility across modern data center environments. It also achieves end-to-end latency under 600 nanoseconds, representing a 40% improvement over the previous-generation ConnectX-5. This dramatic latency reduction provides a non-blocking data path critical for high-performance distributed computing workloads.
Hardware Acceleration Engine
The ASAP2(Accelerated Switch and Packet Processing) technology in ConnectX-6 VPI revolutionizes traditional network architectures by decoupling the data plane from the control plane through hardware offloading. For instance, virtual switching and routing functions (vSwitch/vRouter) can be executed directly on the NIC itself, delivering over 5x the performance of software-based solutions while reducing CPU utilization to less than 1%.
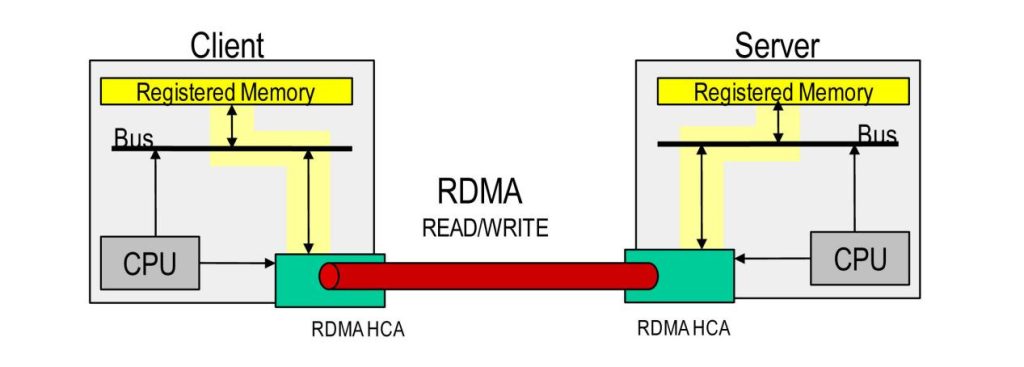
In machine learning workloads, the deep integration of RDMA (Remote Direct Memory Access) and GPUDirect technologies enables direct GPU-to-GPU data transfers across nodes without passing through host memory. This drastically reduces parameter synchronization latency from milliseconds to microseconds. For example, in the NVIDIA DGX A100 system, eight GPUs connected via ConnectX-6 VPI demonstrated a 30% reduction in model training time. Additionally, the adapter’s support for NVMe over Fabrics (NVMe-oF) reduces storage access latency by up to 60%, significantly accelerating cold data retrieval and real-time analytics workflows.
Security and Compliance
To address advanced persistent threats (APTs) in data centers, the MCX653106A-HDAT offers a comprehensive end-to-end encryption architecture. It leverages hardware-offloaded IPsec and TLS encryption engines during data transmission, supporting algorithms such as AES-256-GCM, with encryption rates of up to 200Gb/s and performance overhead below 2%. For data at rest, it employs XTS-AES block encryption, ensuring secure static data protection. The NIC is also equipped with an integrated Layer 4 stateful firewall and DoS attack detection module, enabling real-time malicious traffic interception. In addition, Root of Trust (RoT) is used to verify firmware integrity and defend against supply chain attacks.
Core Capabilities for Accelerating Machine Learning
High Throughput and Low Latency
The NVIDIA ConnectX-6 VPI delivers up to 200Gb/s bandwidth and sub-microsecond latency, enabling near real-time parameter synchronization for machine learning training workloads. In large-scale language model training, it achieves a message rate of 215 million messages per second, reducing inter-node gradient synchronization time to less than one-fifth of traditional TCP/IP-based solutions.
The NIC also supports RoCE (RDMA over Converged Ethernet), enabling zero-copy data transfers by bypassing the OS kernel to access GPU memory directly. Combined with adaptive routing algorithms and hardware-based congestion control, it maintains over 99.9% link utilization even under heavy multi-tasking conditions—ensuring stable, uninterrupted training and minimizing the risk of network-induced disruptions.
GPU Collaborative Acceleration
The deep integration between ConnectX-6 VPI and NVIDIA GPUs is reflected across several key dimensions:
GPUDirect RDMA: Enables direct memory access between GPUs and the NIC over the PCIe bus, allowing seamless GPU-to-GPU communication across nodes without involving the CPU.
NVLink and InfiniBand Topology Fusion: Within a single node, NVLink provides up to 600GB/s of direct GPU-to-GPU bandwidth. Across nodes, ConnectX-6 leverages InfiniBand to build a lossless Layer 2 network, forming a global memory pool through an “NVLink over Fabric” architecture. This hybrid design allows efficient distribution of massive model parameters across thousands of GPUs, accelerating large-scale deep learning training.
Multi-Node Expansion
The ConnectX-6 VPI supports dual protocols of HDR InfiniBand and 200GbE Ethernet, enabling the construction of scalable architectures ranging from a few nodes to thousands of nodes. It supports network topologies such as Fat-Tree and DragonFly+, allowing a single cluster to scale up to tens of thousands of nodes. Leveraging SHARP technology, ConnectX-6 offloads collective communication operations like All-Reduce to the switch hardware, boosting communication efficiency in large-scale clusters by up to 80%. The adapter also offers deep integration with Kubernetes and NVIDIA Magnum IO, facilitating dynamic resource allocation in containerized environments. In training trillion-parameter models like GPT-3, ConnectX-6’s multi-node scalability enables model parallelism at the scale of 4096 GPUs, reducing communication overhead from 25% to less than 8%.
Optimization Solutions for Big Data and Storage Scenarios
Improved Efficiency of Ultra-Large-Scale Data Processing
In petabyte-scale data processing scenarios, traditional network architectures often suffer significant performance degradation due to bandwidth bottlenecks and CPU overload. The NVIDIA ConnectX-6 VPI addresses these technical bottlenecks with the following features:
- Leveraging the ASAP2 acceleration engine, it offloads tasks such as data compression and checksum calculation from the CPU to the NIC hardware, freeing up 90% of CPU resources.
- Supports adaptive routing algorithms and dynamic load balancing to mitigate network congestion.
- It also supports direct remote storage attachment as a local device via NVMe over Fabrics (NVMe-oF), bypassing the traditional file system stack.
NVMe over Fabrics and RoCE Support
The ConnectX-6 VPI features advanced protocol stack optimizations and supports RoCE v2, enabling sub-microsecond remote storage access over Ethernet. Compared to TCP/IP, NVMe-oF over RoCE reduces CPU utilization by 70% and increases throughput by 4 times. The NIC’s built-in NVMe-oF target engine can directly process storage commands, reducing software stack overhead. It also supports both InfiniBand and Ethernet, meeting the requirements of hybrid cloud environments.
Dual Acceleration of Cold Data and Real-Time Analysis
ConnectX-6 VPI provides efficient processing capabilities and real-time analytics optimization for hot and cold data tiering throughout the data lifecycle. Based on a hardware encryption engine, it implements block-level confidentiality for cold data and supports erasure coding offload, significantly reducing data reconstruction time. It also leverages QoS priority tagging to allocate sufficient bandwidth for real-time traffic, while cold data processing only consumes leftover resources, ensuring zero business interruption.
Conclusion
The NVIDIA MCX653106A-HDAT, with its 200Gb/s bandwidth, sub-microsecond latency, and full-stack hardware acceleration capabilities, redefines the core value of intelligent networking in modern data centers. As an integrated engine combining networking, storage, and computing, it leverages technologies such as RoCE and ASAP2 to address communication bottlenecks in distributed machine learning training, enabling GPU memory direct access and seamless multi-node scaling. In large-scale data processing scenarios, NVMe over Fabrics and hot/cold data tiering acceleration technologies significantly improve storage efficiency and real-time analytics responsiveness. Meanwhile, hardware-level encryption technology provides reliable security guarantees for high-security environments such as finance and government. Whether building AI training clusters, optimizing real-time data analytics, or upgrading hybrid cloud infrastructure, ConnectX-6 VPI serves as a cornerstone for enterprises transitioning into the era of compute-intensive workloads, delivering comprehensive breakthroughs in performance, security, and energy efficiency.
Frequently Asked Questions (FAQ)
Q:What data rates does the MCX653106A-HDAT support?
A:ConnectX-6 VPI supports dual protocols: InfiniBand HDR/HDR100/EDR (200/100/100Gb/s) and Ethernet (200/100/50/40/25/10Gb/s), adapting to different network environments.
Q: What scenarios are best suited for using ConnectX-6 VPI?
A:Typical use cases for ConnectX-6 VPI include: AI/ML distributed training, ultra-large-scale data analysis, HPC, real-time storage, and cold data management.
Q:How to test the RDMA performance of ConnectX-6?
A:You can use the ib_write tool to test the effective bandwidth of the network card through ib_write_bw -a (server) and ib_write_bw -a (client), and the end-to-end latency can be tested through the ib_write_lat -a command.
Share on Social:



- PREV: Choosing the Right 400G Cable: DAC, AOC, ACC or AEC
- NEXT: Null